


在自动驾驶规模,每每会听到数据飞轮这个认识。为什么特斯拉的FSD能从频繁收受进化到近乎老司机的才气,迭代速率甩开传统开发模式几个量级?为什么华为、小鹏这么的厂商都在不计老土产货铺设数据闭环?谜底就藏在飞轮这两个字里。今天就和大众来聊聊企业是怎样作念好数据飞轮的。
这个飞轮是怎样转起来的?
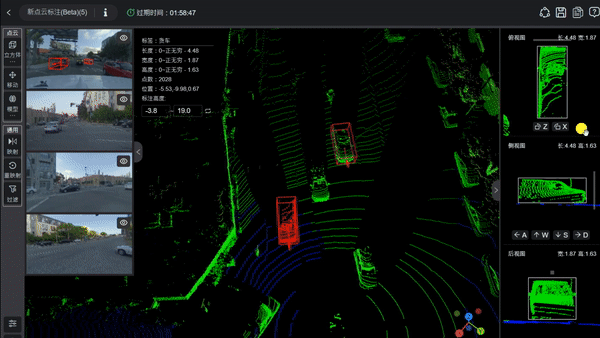
数据飞轮简便意会,便是一套让自动驾驶系统从真实驾驶中自我学习、不竭进化的工程闭环。它不错完成车辆积聚数据、数据回传云表、云表完成自动标注与模子训练、新模子通过OTA部署回车端,车辆赓续积聚新数据进入下一轮轮回等一扫数运转链路。当这套链路中各按序的自动化进程裕如高时,飞轮就概况在极短时候内完成发现问题、训练转变、考证上线的齐全周期,轮回来去地晋升智驾才气。
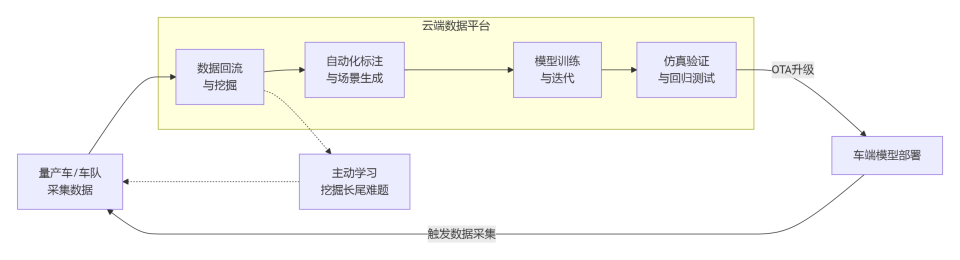
图片源自:智驾最前沿
当前行业对数据飞轮的竞争,已从谁独特据转向谁的迭代效力更高。特斯拉从FSD V12的端到端模子与影子模式构建了业界效力最高的数据闭环,FSD累计行驶里程逾越16亿英里,且仍在加速。华为则通过八爪鱼平台将数据闭环才气封装为可委派的产物,为车企提供数据、标注、训练、仿真、合规等一站式器用链。Waymo莫得照搬行业流行的端到端大模子路子,而是构建了独到的驾驶员、模拟器、评价者三位一体闭环架构,强调安全可考证。英伟达则凭借Cosmos寰宇基础模子与Omniverse仿真平台,将数千英里真实驾驶数据扩展为数十亿英里臆造驾驶里程,用合成数据角度为飞轮提供能源,关于各企业的具体实施决策,将在第四章节与大众详备聊一聊。
车端怎样精确积聚高价值数据?
数据积聚是飞轮的起始,一辆具备高阶智驾才气的车辆每天产生的传感器数据可达TB级别,若是全量回传,网罗老本和云表存储老本难以承受。因此,车端必须具备在行驶中自动筛选高价值场景的才气,这是飞轮能否低老本运转的第通盘关卡。
特斯拉通过影子模式来齐备这一按序,在东说念主类驾驶员操控车辆时,FSD算法在后台同步运行并寂寞作念出决策判断,但不铁心车辆。系统实时比对算法判断与驾驶员现实操作,一朝两者出现权臣不合(如算法以为应该延缓而驾驶员加速通过),就判定该场景为特地工况,自动触发数据回传。这种机制将东说念主类驾驶员的当年操作算作免费的真值参照,系统无需任何东说念主工侵犯就能自动发现模子发扬欠安的场景。

图片源自:网罗
影子模式是一种被迫触发策略,而主动学习则是云表主动向车队发起数据积聚央求的一种步地。当算法团队识别出模子对某类场景处理才气不实时,会向全球车队下发包含办刑场景特征神态的轻量级触发器。车辆在行驶中不竭匹配这些特征,一朝掷中,就不错将对当令段的数据打包上传。这种缺什么、找什么的定向积聚方式,在铁心传输老本的同期大幅晋升了进入训练集的数据价值密度。
华为乾崑决策也给与了同样架构,通过量产车数据积聚网罗与云基础按序的配合,齐备端云协同的定向数据筛选。其智驾数据闭环模子不错低老本、快速得回高价值训练和仿真数据,同期通过端云协同增强复杂场景的意会与决策才气。小鹏则将用户侵犯行为算作关节触发信号,车端回传用户侵犯时的操作、环境和系统景色三维信息,以定点攻克收受场景。
数据上云后如哪里理和训练?
数据回传后,最初要作念的是标注按序,传统标注方式多数依赖东说念主工,一辆车一天产生的激光雷达点云可能需要上百名标注员处理数日。为撑持飞轮的高频迭代,标注按序的自动化是必须惩处的问题。
4D自动标注是当前行业的主流决策。4D意味着在3D空间坐标之上加入时候维度,对点云和图像数据进行跨时序的承接标注,标注末端能更好地撑持BEV感知模子的训练。阿里云的ADS 4D标注平台就不错通过AI预标注技艺对点云进行初步识别,再由东说念主行状念微调修正,同期引入自动化质检逻辑,将标注精度从行业通用的98%晋升到 9.2%,年度完成数亿帧3D点云处理。标贝科技的4D-BEV上亿点云标注系统则愚弄大模子进行多模态预识别,从空间和时序维度对车辆、行东说念主和路标等办法进行多视角标注,将百亿点云的标注周期从月级压缩到周级。
图片源自:网罗
学术界也在鼓吹标注技艺的底层探索,SAM4D决策引入和洽多模态位置编码(UMPE),将相机和激光雷达的特征在分享3D空间中对都,齐备跨模态领导与交互,概况对相机和激光雷达流中的汗漫办法进行分割。这些技艺共同标的是让东说念主的变装从标注操作家转变为质料审核者。
标注完成后就会进入模子训练按序,大模子时间下,算力基础按序成为决定迭代速率的关节。小鹏在2025年科技日露馅,其云表训练集群范围达3万卡,基座模子参数目达到720亿,训练数据接近1亿clips,可齐备每5天完成一次全链路迭代,等效遮掩东说念主类司机6.5万年的极限场景。腾讯部署的车云一体决策则在数据经管层面发力,通过和洽数据目次经管、端到端数据血统跟踪和漫步式异构算力逶迤,将数据发面前候裁汰90%,存储老本诽谤50%,策画老本诽谤75%。火山引擎建议的全模态数据湖决策,通过引入Lance数据湖步地齐备超大范围元数据神态和高档索引,惩处了多模态数据异构处理和多团队协同的效力瓶颈。
图片源自:网罗
仿真考证是模子上车前的临了一步,华为的仿真平台预置了25万以上仿真场景库,遮掩高速、城区、停车等场景,并赞成基于基础场景库泛化生成千万级繁衍场景,单日可完成千万公里的并行仿真里程。阿里云则整合Omniverse仿真平台与寰宇模子Cosmos,在臆造环境中完成模子评测后再部署到旯旮开辟。
还有少许要提的是,合成数据在飞轮中上演的变装越来越重。跟着智驾系统才气的晋升,实车积聚的数据中灵验信息密度不竭诽谤,譬如系统仍是能冒失雨天场景后,雨天的绝大多数积聚数据就失去了训练价值,信得过有价值的只剩暴雪、台风等更极点的长尾场景,此时合成数据就起到了作用。2023年到2025年间,合成数据在训练数据中的占比从20%~30%晋升到了50%~60%,已成为补充长尾场景的主要方式。这也意味着飞轮的燃料开首正在从纯实车积聚向实车积聚+合成生成的搀杂模式转变。

几家企业走的不同路子详解
行业对数据闭环的必要性早已酿成共鸣,但具体到齐备旅途上,每家企业都给出了总计不同的解法。这些不合背后,现实是各家对本身政策定位的考量。
特斯拉算作数据飞轮模式的标杆,其中枢上风配置在一套垂直整合的全栈架构之上。全球数百万辆概况运行FSD的车辆组成了一个浩大的漫步式数据积聚网罗,无码国产精品一区二区在这个网罗中,影子模式和定向触发机制负责高效筛选有价值的数据,当算法判断与东说念主类驾驶员的操作出现不合时,系统会自动上传相干场景数据,扫数过程无需东说念主工介入。近期更新的强制收受原因填写功能,则为每一条收受数据赋予了明确的分类标签,进一步晋升了数据标注的质料。在云表,自研的Dojo超算与自动标注器用买通了训练链路,新模子可通过OTA通说念奏凯部署回车端。从芯片到算法再到数据,这条齐全的链路全部掌执在特斯拉我方手里,省去了跨供应商合作的摩擦老本。

图片源自:网罗
特斯拉建议的Data Engine框架将这一轮回梳理得愈加明晰。它最初积聚特定场景的驱动素材,然后向全球车队央求扩展同样场景,接着对数据进行自动标注并参加训练,通过影子模式考证成果后,再启动下一轮轮回。这套框架让数据飞轮的每一个按序都酿成了明确的反馈链路。近期FSD V14的发布进一步开释了技艺后劲,模子参数范围扩展至V13的十倍,引入了人人搀杂架构和强化学习,推动智驾才气不竭跃迁。
华为的移交与此不同,算作增量部件供应商,它通过八爪鱼平台为车企提供一站式的数据闭环器用链,遮掩数据处理、场景挖掘、标注、模子训练、仿真测试、合规职业等齐全按序,底层硬件基于自研昇腾AI处理器,盘古预标注大模子为其提供AI才气撑持。这套决策的关节在于,数据闭环被封装成一个可委派的产物,车企可按需集成,无用每家都从新自研。在算法架构上,ADS 5.0搭载的WEWA架构采选了另一条路,行业主流标的是VLA模子,华为则以为中间的言语层会引入蔓延和信息亏空,因此转而给与WA模子,奏凯从多模态感知数据映射为行驶轨迹铁心指示。云表的World Engine则以极高密度生成极点驾驶场景进行训练,在负责起程前完成高强度的臆造考证。

图片源自:网罗
Waymo的路子与前边两家截然有异,它莫得押注更大的端到端模子,而是构建了一套以安全可考证为优先级的AI生态系统,由驾驶员模子、模拟器和评价系统三个组件组成闭环。三者的底层由和洽的Waymo基础模子驱动,里面给与了快想考与慢想考的双系统架构,一个负责交融多传感器数据进行毫秒级实时决策,另一个则基于视觉言语模子对陌生复杂场景进行深度语义推理。
Waymo的飞轮不错意会为表里两层,内环是基于强化学习的仿真到考证再到上车的闭环,外环则是实车测试的反馈闭环。评价系统负责标记问题,系统据此生成转变行为,经过模拟器高强度的压力考证和安全框架审核后,才气部署到真实说念路。这套架构让Waymo的模子并不依赖东说念主类教化来学习,而是从本身逾越一亿英里的总计自动驾驶现实数据中奏凯进化,系统安全性相较东说念主类驾驶晋升十倍以上。
英伟达则从算力和仿真器用链的角度切入数据飞轮,在2026年GTC大会上,它发布了物理AI数据工场蓝图,这是一个灵通的参考架构,用于和洽并自动化训练数据的生成、增强与评估。蓝图的中枢包含三个组件,Curator负责数据处理和标注,Transfer用于数据扩展和种种化,Evaluator则实施自动评分和考证。借助Cosmos寰宇基础模子,开发者不错将有限的真实驾驶数据逶迤为大范围种种化的数据集,遮掩现实中难以积聚的长尾与旯旮场景。这套数据工场模式的意旨在于,它大幅诽谤了对实车积聚数据的依赖,通过仿真生成的种种化场景来加速端到端自动驾驶的开发。
小鹏汽车采选了一条相对激进的技艺路子。它在2025年科技日发布了第二代VLA大模子,并在2026年完成量产推送。该模子给与端到端架构,跳过了传统的视觉识别、言语转译、动作实施分步经过,奏凯将视觉信号映射为驾驶指示,决策蔓延被压缩在80毫秒以内,反映速率较前代晋升十二倍,百公里收受次数减少三分之一以上。与此同期,小鹏Robotaxi已负责量产下线,搭载四颗图灵AI芯片,算力达到3000TOPS,给与纯视觉决策搭配第二代VLA模子,齐备了L4级自动驾驶才气。在数据层面,小鹏将物理寰宇模子比作引擎,将数据比作燃料,数据的数目和质料奏凯决定了引擎能否高效运转。

图片源自:网罗
Momenta自创立之初就建议了一个飞轮两条腿的政策,让智能辅助驾驶与Robotaxi分享团结个数据闭环和模子底座,通过两个应用标的的协同来加速飞轮运转。在2026年北京车展上,Momenta晓谕R7强化学习寰宇模子齐备量产首发,CEO曹旭东曾打过一个譬如,数据就像贫矿,原始数据只孝顺了价值泉源的特别之一,剩下的九成来自飞轮的体系才气,其中又包括架构才气和组织才气。现在搭载Momenta系统的量产车辆已逾越八十万台,且增速不竭加速,飞轮效应的加速趋势正在数据层面得到考证。
从扫数行业来看,各家齐备旅途虽有不同,但底层演进标的高度一致,那便是从模块化架构走向和洽的端到端模子,数据闭环的迭代周期从天级向小时级压缩。跟着合成数据占比不竭晋升、全经过自动化器用链逐步部署,行业的中枢矛盾正聚焦于长尾场景遮掩与老本铁心之间的均衡。
